
The Coefficient of Variation
Combining a measurement of the typical and a measurement of the dispersion about the typical

Introduction
Humanity has long understood that, given some phenomenon, it is not enough to describe what is typical about that phenomenon - one needs to describe (at the very least) the variety of values one might encounter when examining the phenomenon. So, if x represents the measurement associated with the phenomenon then one way to measure the typical value of x is to calculate the arithmetic mean or average, call it a(x), by adding all the available values of x together and dividing the result by the number of such values. To describe the variation, one way to do this is to calculate the standard deviation, call it s(x), by calculating the deviation of x from a(x) for all available values then calculating the sum of the squared values of these deviations and dividing by one less that the number of deviations before taking the square root. There’s a simpler way to calculate s(x) and division with one less than the number of deviations needs explaining (briefly, if you have n deviations which necessarily total to zero, you have only n - 1 “pieces of information”) but for the man in the street one need only point out that in Excel, a(x) is calculated using the function AVERAGE() and s(x) is calculated using STDEV.S().
So, given x, a(x) measures the typical values of x while s(x) measures the typical deviation from x. When describing x, this is often summarised as “a(x) ± s(x)”.
Calculating a(x) and s(x) does not make sense for every x you encounter. For example, if you observe the numbers on the backs of the starting players of a rugby match (1, 2, 3, …, 15) you’ll find that a(x) is 8 and s(x) is 4.32 (rounded to two decimal places), whether this is a match between two high schools or between the Springboks and the All Blacks. Knowing a(x) and s(x) for this x is uninformative. This is because one must understand that measurement is the act of assigning numbers to objects in such a way as to communicate a characteristic of the objects. In the case of the rugby players, the numbers assign only an identity to the object - in S.S. Stevens’ classical 1946 paper, this is measurement on the nominal scale; one is merely naming the objects with the numbers assigned.
One can also assign numbers to objects to communicate the order of the objects - without communicating anything about the distance between the objects. If I tell you this horse came first (“1”), that one came second (“2”) in a photo-finish, that would also be true in a case where this horse came first and that horse came second - but arriving an hour later. This is an example of measurement on an ordinal scale. Back in the day I tried hard to convince people that there was a more appropriate method for the analysis of such data, a method which carefully avoids both a(x) and s(x), but I know for a fact that I convinced few in the industries concerned!
For the purist, the use of a(x) and s(x) only makes sense when measuring on the interval or ratio scale. In the first case the numbers assigned reflect only the “distance” between objects and such measurements can be recognized by the fact that a measurement of zero (“0”) has an arbitrary meaning. The obvious illustrative example in this case is the measurement of temperature. If I do that using the Celsius scale (where “0” measures the freezing point of water at one atmosphere of pressure) then I must be careful not to say that that something measuring 40°C is “twice as hot” as something measuring 20°C. That’s obvious from the result of converting to the Fahrenheit scale - the object measuring 104°F is now “almost three times hotter” than the object measuring 35.6°F. Neither quoted statement is true - indeed, both are misleading, because the measurements are communicating distance, not relative distance. To avoid such erroneous statements, one must convert to a scale where the measurement “0” is assigned in the cse of “nothing”, “none”, “absent”. Such a scale is called a ratio scale and in the case of temperature, that’s the Kelvin scale.
Oh! In the case of the Fahrenheit scale “0” has an exceptionally arbitrary definition (because this value was selected for a point initially meaningful to Fahrenheit but which he later discarded by adding 2 to define his scale!). It would not be wrong to say that “zero has no physical meaning on the Fahrenheit scale”.
Ratio scale measurements are dime a dozen. How tall are you? How tall would you be if I said your height was zero? If I had three people, one 2 meters tall and two 1 meter tall, I could arrange the tall person lying on a bed next to the two short people, the one followed by the other, and you’d agree that the tall person is twice as tall as the short people. The point is that ratio scale measurements identify (nominal), communicate order (“he’s taller than them”), communicate difference, interval, (“he’s taller than him by the height of the other shorty”) and they communicate relative value (“he, 2, is twice as tall as them, 1”).
The coefficient of variation, CV, C(x), can only be used for ratio scale measurements and is defined to be the value of s(x) divided by a(x). It is usually expressed as a percentage. It can be used in all sciences but I’m most familiar with its use in Biology. Perhaps the most spectacular use is in Archaeology. Imagine a primate species which today has a long index finger which it uses to dig for insects. Imaging an archaeological collection of specimens of this species going back in time. An analysis of finger length of samples 20,000 years ago, 10,000 years ago and current might show short fingers in the primordial specimens and CVs of 6%, 21% and 5% respectively, allowing the researcher to conclude that the long finger evolved 10,000 years ago. (Typically, the data might be grouped in various ways until a grouping was found which reflected the two finger lengths and the age during which a variety of finger lengths existed; the point in time when a large CV indicated great variability).
A detour
The CV has a property which, search as I might, I’m unable to find in Google searches. This property was taught to me by my teacher, mentor, colleague and inspiration, IMR van Aarde, deceased Professor of Biometry at the University of Stellenbosch. You can find his magnum opus here. He was known by his middle name, Mauritz.
Mauritz made two empirical observations (or someone pointed them out to him) and he invented a method to justify the second observation:
1. In a stable population, the CV of one-dimensional measurements (height, index finger length) tend to be in the region of 5%;
2. The CV of two-dimensional measurements (like leaf area) tend to be twice that of one dimensional measurements and the CV of three-dimensional measurements (like fruit size) tend to be three times that of one-dimensional measurements. The latter can be extended, cautiously, to measurements proportional to volume (like body mass).
Write z for a two dimensional measurement and consider an specimen which is larger than typical by the typical deviation, i.e one with a measurement of
z = a(z) + s(z) = a(z)×[ 1 + s(z)÷a(z) ] = a(z)·[ 1 + C(z) ]
This two-dimensional measurement can be thought of as being constructed from two one-dimensional measurements, as follows

Taking z to be width (x) times length (y) and assuming the values of these two measurements to be
a(x) + s(x) and a(y) + s(y)
respectively, we can multiply width by length to get
[ a(x) + s(x) ] × [ a(y) + s(y) ] = a(x)·[ 1 + C(x) ] × a(y)·[ 1 + C(y) ]
= a(x)·a(y)·[ 1 + C(x) + C(y) + C(x)·C(y) ]
Comparing the last formula to the one above the diagram we can suggest that:
1. a(z) is approximately equal to a(x)·a(y);
2. If it is true that C(x) and C(y), as the CVs of one-dimensional measurements, are approximately 0.05 (5%) then their product is roughly 0.0025, an amount which is negligibly small compared to C(x) and C(y);
3. So, drawing the threads together, we can suggest that C(z) is approximately equal to C(x) + C(y). The result is clearly also true (as an approximation) for a three-dimensional measurement.
Googling for examples, I found an interesting one on Quora. Unable to link directly to the entry, I copied it and pasted it:

As I would expect, the CV of height is roughly 5% and that of weight roughly three times that of height but I’d love to know why the CV of arm circumference is almost 6 times what I’d expect it to be. The data appears to be real.
Eskom’s data from 01/04/2019 to 21/01/2024
If one applies to Eskom, they will supply data, going back roughly five years (1757 days in the case of the dataset I received). The data is hourly data, in MW for various metrics, described by a column heading. Calculating the CV in select cases, I offer following summary.

I cannot say with certainty what “Thermal Generation” is. I think it’s mainly coal. Nor can I offer an interpretation of the value of 10.6% calculated from the 42,168 values in the dataset. Given that Eskom is performing poorly I suspect that it is a large value - but, if I’m correct that this is a measurement for mainly coal, it’s a useful reference point.
The CV for nuclear is difficult to interpret. The data suggests that values close to three key values dominate. Either none of the two 930 MW units is functioning (output is 0) or one is functioning (output is 930 MW) or both are functioning (output is 1860 MW). To explore this idea, I created a small dataset of one 0, seven 930’s and seven 1860’s and calculated a CV of 43.6%. It appears that the nuclear CV is more or less what one would expect.
For renewables, Wind has a CV of 55.1%, PV is a massive 125.2%, CSP (97.4%) is better than PV but, surprisingly, worse than wind. For the total the CV is roughly the same as the dominant contributor, Wind. There’s a hint that a mixture is better than a single source in that the total CV is 0.5 less than Wind’s CV but I find it difficult to become excited by such small difference.
In my opinion, the most important takeaway is that renewables are, relatively-speaking, five times as variable as thermal generators.
Addressing a claim about the reliability of nuclear
Prof Anton Eberhardt is a vocal commentator on energy in South Africa. This a message (“tweet”) he sent out on the platform now called X.
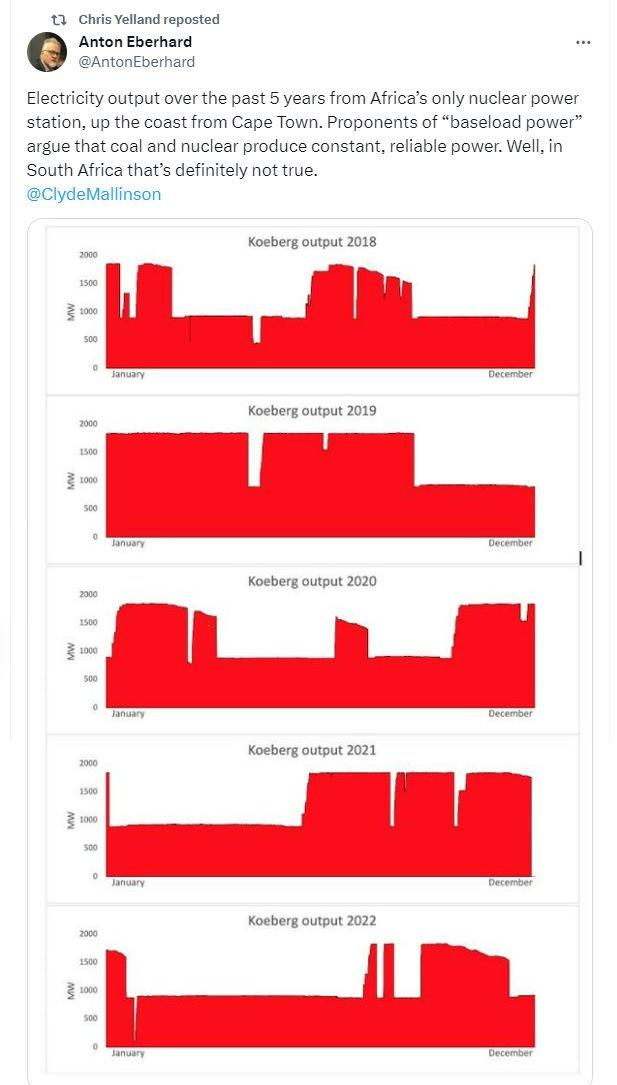
The pattern we see in the graphs is as described above - there are three key values, 0, 930 or 1860. The actual output is a value close to one of those three values. Output is at one of those three values for months at a time.
Nuclear’s CV would, in my opinion, be improved by having more reactors. The value of 35.1% calculated for the dataset I received is the consequence of having just two reactors. Yet that value is still lower than the value for Wind, PV and so forth. If Prof Eberhardt is dismissive of nuclear because of it’s variability, he should apply his criteria uniformly and concede that if nuclear can’t do the job, renewables cannot either!